
博客系统中很重要的一点就是关于分类和标签,当文章数量过多时,通过分类和标签,阅读者就能比较快速的找到想要阅读的文章,同时也能够清楚的了解与当前文章有所关联的其它文章。
当我开始搭建博客并设计分类与标签时,我犯难了。标签很好理解,可以看做是一篇文章最核心的主题、属性;但关于分类,我想了许久也没想明白该如何设计才比较合适。
例如:一篇文章的分类是否和标签一样可以多个?分类是否需要分级?等等。。。🤔
最后我意识到:如果将分类设计的很复杂、过多的细分就模糊了分类与标签的区别,反而使得分类越来越标签化。索性最后只留下了技术、工具、生活、随笔四类,如此简化的设计之后,终于收货一丝愉悦感。🎉
最终要实现的目标:
- 可以通过 Category 、tag 过滤出对应的文章列表
- 点击文章跳转至对应详情页
目标比较简单,就下来就开始去实现。
1. 方案一:jekyll-archives 实现
查阅资料之后发现了一个插件: jekyll-archives,此插件能够通过配置 _config.yml 文件,自动识别 post 头信息中的 category/categories、tag/tags 生成对应的静态资源,并可以通过类似 /categories/:categoryName 这样的地址访问对应分类下的文章资源。
首先看一下 _config.yml 文件的相关配置:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# _config.yml
plugins:
- jekyll-archives
jekyll-archives:
enabled:
- tags
- categories
layouts:
tag: tag
category: category
permalinks:
tag: tags/:name/
category: categories/:name/
点击查看 jekyll-archives 文档 可以详细了解各个配置项的意义。
1.1. 缺陷
刚开始在本地环境中开发时一切都很顺利,直到部署到 GitHub Pages 中,许多问题才开始浮现:
-
首先是无法正常识别非英文的 category 和 tag。
这个问题直接导致通过
/categories/:categoryName和/tags/:tagName这样的路径访问博客时,所有中文 category、tag 直接 404。。。🙃 -
另一个问题是:jekyll-archives 并不是 GitHub Pages 推荐插件
GitHub Pages 为了安全考虑,除了 白名单 中的插件可以使用外,其他插件都无法在 GitHub Pages 中正常使用,jekyll-archives 就不包含在白名单之中。
如果想继续使用 jekyll-archives,官方给出的解决办法就是在本地将 Jekyll 项目转化为静态资源文件再上传至 GitHub,而不能再是 Jekyll 项目源文件。
最后,综合考虑成本以及 Jekyll 现有的功能,最终还是决定放弃 jekyll-archives,而是使用 Jekyll 现有的能力来实现 Post、Category、Tag 的资源关联交互。
2. 方案二:Jekyll 原生实现
根据目标得知,需要得到 Category 、Tag 对应的文章信息,并且文章信息至少需要包含标题及对应的链接地址。如何得到这些信息呐?
通过查看 Jekyll 文档,可以发现 Jkeyll 中有一个全局对象 site,其包含了很多的关键信息:
| 变量 | 说明 |
|---|---|
site.pages |
所有页面信息的列表 |
site.posts |
所有文字信息的列表 |
site.categories / site.categories.CATEGORY |
所有分类信息的列表 / 所有在分类 CATEGORY 下的文章 |
site.tags / site.tags.TAG |
所有标签信息的列表 / 所有在标签 TAG 下的文章 |
有了这些数据的支持,这下就方便多了,接下来就是考虑该如何去使用这些数据。
2.1. 思路一:解析页面渲染
在 _includes 文件夹下创建 categories.html 和 tags.html 文件,使用 site.categories 和 site.tags 生成页面内容。
以 categories.html 为例:页面为上下结构,上部分为 category 列表;下部分为每一个 category 所对应的文章列表块。最后通过 JS 脚本控制点击上部分的 category 时,下部分对应文章列表块的显隐。
tags.html 实现方式同上。
2.2. 思路二:生成资源数据
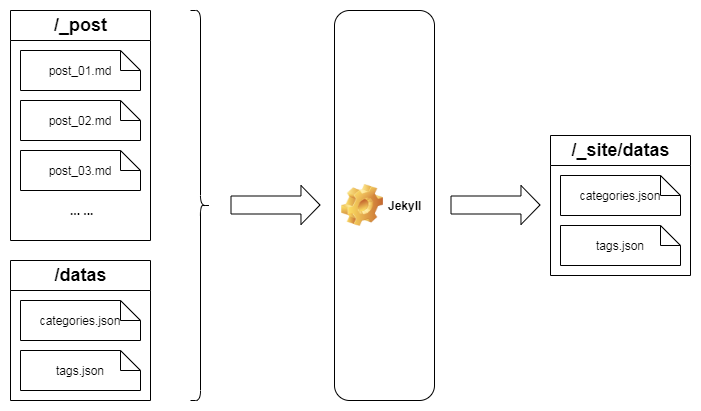
利用 Jekyll 的能力,我们可以提前构造一份包含 Category 和 Tag 相关资源的数据文件(json 格式),当博客部署之后,这份数据文件就可以被当做静态资源被访问,拿到数据之后就可以实现这个功能。
首先我们需要使用 site.categories 、 site.tags 构造这份文件,以 /datas/categories.json 为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
---
---
{
"categories": [
{% for category in site.categories %}
{
"name": "{{ category | first }}",
"url": "{{ site.baseurl }}/categories#{{ category | first | slugify | url_encode }}",
"datas": [
{% for post in category.last %}
"{{ post.title }}"{% if forloop.last == false %},{% endif %}
{% endfor %}
]
}{% if forloop.last == false %},{% endif %}
{% endfor %}
]
}
❗注:文件最开始的两行不能省略,省略后将不会被 Jekyll 识别并解析
部署之后,此文件将会被 Jekyll 解析生成最终内容符合 JSON 规范的目标文件:_site/datas/categories.json,最后我们可以通过 http 的方式获取这份文件,得到我们需要的数据。
3. 总结
最终通过 Jekyll 提供的能力实现了 Category、Tag 的交互,经过这个过程,对 Jekyll 有了更全面的了解,同时也收获了一些经验:
-
思考清楚再编码
-
多查阅官方文档
文中有不足之处,欢迎多多拍砖。🚀